一、体系管理
1.体系根本管理和维护
1.1 Tab:补全。
Tab一次,输入的内容可以大概唯一标识,直接跳出下令(补全);
(echo $PATH:体系情况变量的路径全部打出来了)
1.2 shell下令利用——快捷键
(shell是一种脚本语言)
1.3 vi / vim利用 :用于编辑文本
1.4汗青下令
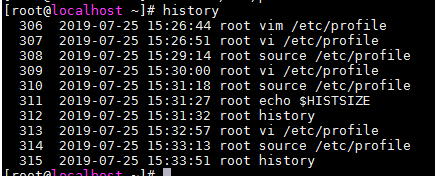
history:查察汗青下令
!+汗青下令的列表行数:直接实行该行的下令(!10:实行第十行的汗青下令)
!$ :实行末了一次的汗青下令
help history ;查察资助
history -w:把汗青下令列表同步到汗青下令文件中
echo $HISTFILE:查察汗青下令文件位置
-c:清空history list。可以用 -r 选项再读返来。
怎样设置 汗青下令的生存数目
echo $HISTSIZE :查察history(汗青下令文件)可生存的汗青下令的条数
vim /etc/profile :进入/profile文件中
HISTSIZE=1000:表现只能生存1000行下令,剩余不被生存
soure /etc/profile :重新加载,更新profile文件内容
怎样设置汗青下令的时间戳,和利用用户
vim /etc/profile:进入/profile文件中,更改汗青下令的行数,然后举行 source
在末了一行编辑:
export HISTTIMEFORMAT="%F %T `whoami`(空格)"
:wq:生存退出
soure /etc/profile:更新profile文件内容
1.5 别名alias
界说别名:
[root@localhost ~]# alias net="vi /etc/sysconfig/network-scripts/ifcfg-eth0"
取消别名:
[root@localhost ~]# unalias net
跳过别名:(\称为转义符)
[root@localhost ~]# \net
让别名永世见效:
编辑bashrc文件:
[root@localhost ~]# vim /etc/bashrc
下末了一行编辑输入:
alias net="vim /etc/sysconfig/network-scripts/ifcfg-eth0"
:wq
[root@localhost ~]#source /etc/bashrc
当“\”+下令:跳过下令
1.6 界说变量
变量分为情况变量、本地变量和局部变量。本地变量 :针对当前shell历程中的某代码片断,通常指函数。
局部变量 :针对当前shell历程;对当前shell之外的别的shell历程,包罗当前shell的子shell历程均无效。
情况(全局)变量 :针对于当前的shell下的全部历程及子历程都见效。
(1)情况(全局)变量:
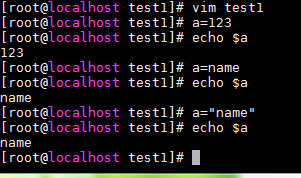
vi test.sh:编辑test.sh文件(.sh是脚本文件)
sh test.sh:实行test.sh文件
(2)
[root@localhost test1]# a="qqqq"
查察:
[root@localhost test1]# echo $a
取消变量:
[root@localhost test1]# unset a
[root@localhost test1]# a=name #当前shell历程,子历程。
[root@localhost test1]# echo $SHELL
1.7 输入,输出
0:标准输入
">"覆盖
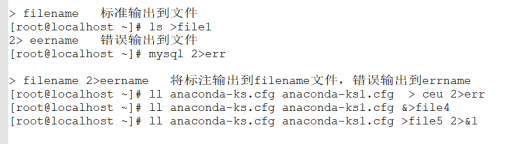
“>”+文件名:标准输出到文件
[root@localhost ~]# ls >file1 // 将ls输出的结果输入到file1文件中
“2”>+错误文件的文件名:错误输出到文件
[root@localhost ~]# mysql 2> err
“>”+文件名 2> errname :将标准输出到filename文件,错误输出到errname
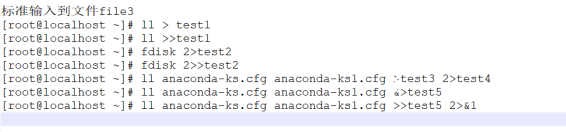
[root@localhost ~]# ll anaconda-ks.cfg anaconda-ks1.cfg > ceu 2>err
[root@localhost ~]# ll anaconda-ks.cfg anaconda-ks1.cfg &>file4
[root@localhost ~]# ll anaconda-ks.cfg anaconda-ks1.cfg >file5 2>&1
输出结果不表现在屏幕上:
/dev/null
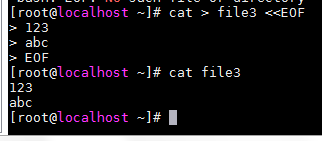
标准输入到文件file3:
标准输出和错误输出都放在同一文件中:(两种方法)
(1)
标准输出和错误输出都放在差异文件中:
扩展:
(1)
$? :判定上一条下令实行是否乐成。若乐成,返回0;若失败,返回非零。
判定网络是否连通:
脚本
1.8特殊符号,通配符
(1)管道符“|” :把上个下令的实行结果交给了下一个下令继承处置惩罚
a、
b、
“tee”:把过滤的结果打印到文件中
mkdir 创建目次
touch创建文件夹
ll:列出结果详细
ls:当前目次下有哪些文件,只列出文件名或目次名
“…” :表现上一级目次
“.” :表现当前目次
【 ` 】:反撇号,把内容还原成下令
将LL中全部已te开头的文件夹表现出来:匹配数字:
[root@localhost ~]# ll test[0-9] [0-9](尖括号间没空格)
[root@localhost ~]# ll test[[:digit:]]*(匹配全部数字)
匹配字母 :
【a-b] 匹配小写字母;【A-Z】和【【:alpha:】】 匹配全部字母
【】匹配括号内匹配到的内容
【^】:表现非的意思,
shell中单引号和双引号的区别:
‘ ’:(单引号)强引用,所见即所得(引号内输入什么,它就直接输出什么)
“ ”:(双引号)弱引用,输出引号内全部内容;若此中含有下令(要反引)、变量、特殊转义 ,会先把变量、下令、转移字符剖析出来,然后在输出结果。
反引号:一样平常用于下令,实行的时间下令会被实行,相当于 $() ,赋值和输出都要用反引号引起来。
[root@localhost ~]# time="我们都是\n好孩子"
[root@localhost ~]# echo -e $time
我们都是
好孩子
[root@localhost ~]# time='我们都是\n好孩子'
[root@localhost ~]# echo -e $time
我们都是
好孩子
//echo -e:表现转意,不受强引或弱引束缚
[root@localhost ~]# time="如今是北京时间:`date`"
[root@localhost ~]# echo $time
如今是北京时间:2019年 08月 01日 星期四 08:24:25 CST
//双引号厘革下令`date`后在输出内容
[root@localhost ~]# time='如今是北京时间:`date`'
[root@localhost ~]# echo $time
如今是北京时间:`date`
//单引号原样输出内容
2.体系管理的常用下令
ls下令
ls - -help:查找资助
ls -a :表现全部的潜伏文件及目次
ls -A :只表现潜伏文件
ls -l 等同于 ll:ll:列出结果详细
ls :表现的是链接文件及链接路径,
ls -L :表现的是链接路径下的真实文件
3.相对路径,绝对路径,pwd
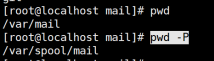
(1)pwd
pwd:表现当前路径
pwd -P:表现链接文件的真实路径
(2)路径
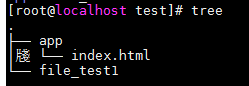
用绝对路径,表现index.html ;/root/test/app/index.html
用相对路径,表现index.html ;app/index.html
(3)cd指令
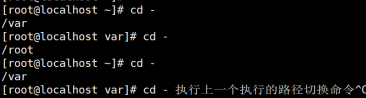
cd - :切换到上一次文件所在的路径
cd ~ :切换到用户的家目次
cd …/ :切换到上层目次
cd …/…/ :切换到上上层目次
(4)date
格式:date "+下令"
date -s :修改体系时间
%H : 小时(00-23)
date +%Y :年份(全称)
%a : 星期几 (Sun-Sat)
时钟表现格式的拼接:明白每个参数寄义
修改体系时间:【扩展:】
#!/bin/bash
time=`date "+%H"`
echo $time
reboot:重启体系
[root@localhost ~]# yum install wget
(5)wget
[root@localhost ~]# yum install wget
Index of /centos/7.6.1810/extras/x86_64/Packages/
[root@localhost ~]# wget http://mirrors.sohu.com/centos/7.6.1810/extras/x86_64/Packages/centos-release-scl-2-3.el7.centos.noarch.rpm
[root@localhost src]# wget -b -c http://mirrors.sohu.com/centos/7.6.1810/extras/x86_64/Packages/ansible-2.4.2.0-2.el7.noarch.rpm /usr/local/src/
[root@localhost src]# wget -P /usr/local/src/ http://mirrors.sohu.com/centos/7.6.1810/extras/x86_64/Packages/ansible-2.4.2.0-2.el7.noarch.rpm
-b :配景运行
-P :指定下载路径
-c :断点续传
(6)uname , free
uname -s:内核名称
cat /etc/redhat-release:查察体系版本
[root@localhost ~]# uname -r
2.6.32-642.el6.x86_64
// 2:主版本号
6:次版本号
32:对次版本的修订次数大概补丁包数
642:编译的次数
el6:版本的特殊信息,el 表现企业版Linux
x86_64:表现64位
(7)free
free -h :查察内存利用情况(带单位)
men:内存
swap:在磁盘是格式化的一个和内存格式雷同的分区
buff:数据读的缓存空间
cache : 数据写的缓存空间
(7)体系管理下令
uptime:查察CPU利用率
当前体系时间,服务状态,运行时间长,多少个用户,5分钟均匀负载;10分钟均匀负载;15分钟的均匀负载。
[root@localhost ~]# uptime
12:37:39 up 1:58, 2 users, load average: 0.00, 0.01, 0.05
top:及时表现体系负载,以及每一个历程的资源占用情况
ps : 查察历程
ps -aux |grep ssh(ssh:长途毗连)
-A:全部的历程均表现出来,与 -e 具有同样的效用
-a :当前终端的历程
-u:用户的历程
-ax :表现详细信息
(8)用户下令
passwd:更改暗码
[root@localhost ~]# whoami
root
[root@localhost ~]# who -m
root pts/0 2019-07-25 16:41 (192.168.134.100)
passwd:修改当前用户暗码
passwd 用户名:修改用户暗码
su:切换用户
su - 用户名:到用户的家目次
[root@localhost ~]# su test
[test@localhost root]$ whoami
test
切换抵家目次:
[root@localhost ~]# su - test
exit:退出当前用户
(回到上一次所利用的用户名):
[test@localhost ~]$ exit
who - m:查察用户
whoami:查察当前用户
(9)文件利用
创建文件或目次:
**mkdir** 目次:只能创建一层目次
mkdir -p 目次1/目次2/目次3…:创建多层目次
[root@localhost ~]# mkdir -p data/data2/data3
touch :创建文件
“>”文件名:创建文件
[root@localhost ~]# touch data/1/2/file3
//在data目次下的 1目次下的 2目次下创建file3文件
[root@localhost ~]# >file2
//创建file3文件
查察文件:
cat :查察文件
cat file1 file2:把两个文件的内容拼接在一起
cat -n 文件:打印行号
cat -s 文件:删去文件内容中的多行空行
cat -E 文件:在行末加上$符号
vi + 行号:光标直接跳到对应的行
[root@localhost data]# cat -n passwd //打印行号
[root@localhost data]# vim +21 passwd //光标直接跳到第21行
[root@localhost data]# cat file1
linux
[root@localhost data]# cat file2
windows
[root@localhost data]# cat file1 file2
linux
windows
diff 文件1 文件2 :查察文件间区别:
[root@localhost data]# diff file1 file2
head :查察文件内容前几行(默认是10行)
[root@localhost data]# head -40 passwd //查察passwd文件前40行
tail :查察文末端(默认是10行)
[root@localhost data]# tail -20 passwd //查察passwd文件的后20行
more :分屏表现
[root@localhost log]# more -10 dmesg.old
//设置一屏十行
Ctrl+F:向下分屏滚动
Ctrl+B:向上分屏滚动
grep文件:过滤文件内容
[root@localhost data]# grep root passwd //过滤在passwd文件中的root。
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
grep ^ 文件:在文件中以^后的字母开头的行
[root@localhost data]# grep ^root passwd //在passwd文件中,以root开头的行。
root:x:0:0:root:/root:/bin/bash
grep -i :不区分巨细写
grep -c :统计打印的行数
grep -n:打印文件行号
grep -v:取反
[root@localhost data]# grep -i root passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost log]# ip a |grep inet
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
inet 192.168.134.112/24 brd 192.168.134.255 scope global ens33
inet6 fe80::5343:1737:e497:16dd/64 scope link
[root@localhost log]# ip a |grep inet |grep -v inet6
inet 127.0.0.1/8 scope host lo
inet 192.168.134.112/24 brd 192.168.134.255 scope global ens33
rm:删除文件
rm 文件名 :删除文件
rm 删除目次 -r:递归删除
rm -r :递归删除一个目次
rm -f :逼迫删除
rm -d :删除空目次
[root@localhost ~]# rm -r data
rm: descend into directory `data'? y
rm: remove directory `data/data1'? y
rm: remove regular file `data/file2'? y
rm: remove regular file `data/file1'? y
rm: descend into directory `data/1'? y
rm: descend into directory `data/1/2'? y
rm: remove regular file `data/1/2/file3'? y
rm: remove directory `data/1/2'? y
rm: remove directory `data/1'? y
rm: remove regular file `data/passwd'? y
rm: descend into directory `data/data2'? y
rm: remove directory `data/data2/data3'? y
rm: remove directory `data/data2'? y
rm: remove directory `data'? y
//递归删除一个目次
rm的工作原理:存在三个file文件i_count:存储管理;i_link:链继承理
mv:移动文件位置
(移动的时间,假如不指定新名字,名字稳固;指定则重定名)
(mv 文件1 文件2:将文件2移动到文件1下)
cp:复制文件
(cp 要复制的文件名 要复制的位置 )
cp -p:带权限复制
cp -a :复制全部
file:查察文件范例
(file 文件名)
[root@localhost ~]# file cp_test
cp_test: empty //cp_test 文件为空
ln -s file1 file3:创建软链接。
软毗连在源文件file1删除的情况下,失效,但本身(file3)仍旧存在;
find:查找路径,
find :查找路径,(默认当前) 参数(-name 文件名, -user ,-type f/s:查找文件)
[root@localhost test10]# find / -name passwd
/sys/fs/selinux/class/passwd
/sys/fs/selinux/class/passwd/perms/passwd
/etc/passwd
/etc/pam.d/passwd
/usr/bin/passwd
[root@localhost test10]# find /etc/ -name passwd
/etc/passwd
/etc/pam.d/passwd
exec :对匹配的文件实行该参数所给出的shell下令。
情势为:command {} ;
留意{}与;之间有空格
[root@localhost test]# find -name test99 -exec rm -rf{} \;
//查找并删除
[root@localhost test]# find -name "test*" -exec rm -rf {} \; //查找全部以test开头的文件并删除它们
Windows体系分盘,而Linux体系不分盘,它只含有一个根/目次,在/根目次下挂载各个文件。
/根目次结构:FHS
Linux体系文件目次:
文件体系:类Unix体系,是一个 “倒挂树” 的情势
bin、sbin:体系下令的二进制文件
boot:存放与体系启动有关的文件
dev:体系装备文件
etc:设置文件
home:用户家目次
lib:库、模块的文件
opt:第三方的安装模块
usr:体系用户
var:与应用干系的文件
[root@localhost /]# ls
bin dev home lib64 mnt proc run srv tmp var
boot etc lib media opt root sbin sys usr
文件利用:
cut:截取
cut -b:按照字节个数来截取文件
cut -b 10-20 ://截取第10到20字节的文件内容
cut -b 10- ://截取第10字节以后的内容
cut -b -20 ://截取第20字节从前的内容
[root@localhost log]# ip a |grep inet |grep -v inet6 |cut -b 10-24
127.0.0.1/8 sco
192.168.134.112
sort:排序
默认是正序分列(sort -n:也是正序)
sort -r :倒序
cat sort |wc -l:统计行数
[root@localhost test]# cat sort |sort -r
6
5
4
3
2
1
[root@localhost test]# cat sort |sort |uniq
1
2
3
4
6
9
//先排序,再去重
查询下令路径:
**which **:查察下令所在路径;
===》可以判定体系有没有安装该下令
[root@localhost test]# which sort
/usr/bin/sort
whereis :查察下令所在路径(包罗文件包名)
[root@localhost test]# whereis pwd
pwd: /usr/bin/pwd /usr/share/man/man1/pwd.1.gz
查询文件所在位置:
find:(见上文)
locate:查找符合条件的文档
 |
猿人部落
( A20190523-0239 )
|
猿人部落
( A20190523-0239 )