文章目次 2 ZooKeeper:由于和谐分布式体系是一个动物园 2.1 ZooKeeper Overview:为客户端开辟职员、管理员和贡献者提供的技能概述文档。 2.1.1 Overview:ZooKeeper 的鸟瞰图,包罗筹划理念和构筑。 2.1.1.1 筹划目标(Design Goals) 2.1.1.2 数据模子和条理定名空间(Data model and the hierarchical namespace) 2.1.1.3 节点和临时节点(Nodes and ephemeral nodes) 2.1.1.4 更新条件和观察(Conditional updates and watches) 2.1.1.5 包管(Guarantees) 2.1.1.6 Simple API 2.1.1.7 实现(Implementation) 2.1.1.8 应用(Uses) 2.1.1.9 性能(Performance) 2.1.1.10 可靠性(Reliability) 2.1.1.11 ZooKeeper项目(The ZooKeeper Project)
2 ZooKeeper:由于和谐分布式体系是一个动物园
ZooKeeper是一种针对分布式应用步调的高性能和谐服务。它在一个简朴的接口中公开了常见的服务——比方定名、设置管理、同步和组服务——因此您不必重新开始编写它们。您可以利用它来实现共识、组管理、向导人推举和参加协议。你可以在此根本上为你本身的特定需求而建。
2.1 ZooKeeper Overview:为客户端开辟职员、管理员和贡献者提供的技能概述文档。
2.1.1 Overview:ZooKeeper 的鸟瞰图,包罗筹划理念和构筑。
ZooKeeper是一个开源的分布式应用步调和谐服务。它公开了一组简朴的原语,分布式应用步调可以在这些原语的根本上实现更高级别的服务,用于同步、设置维护、组和定名。它被筹划为易于编程,并利用了一个数据模子,其风格雷同于文件体系的目次树结构。它运行在Java中,并具有Java和C的绑定。
众所周知,和谐服务很难做好。它们特别容易出现竞争条件和死锁等错误。ZooKeeper背后的动机是减轻分布式应用步调从零开始实现和谐服务的责任。
2.1.1.1 筹划目标(Design Goals)
ZooKeeper is simple. ZooKeeper允许分布式进程通过与标准文件体系构造雷同的共享条理定名空间相互和谐。名称空间由数据寄存器(用ZooKeeper的话说,称为znodes)构成,这些寄存器雷同于文件和目次。与筹划用于存储的范例文件体系差别,ZooKeeper数据生存在内存中,这意味着ZooKeeper可以实现高吞吐量和低耽误数。
ZooKeeper实现非常器重高性能、高可用性和严格有序的访问。ZooKeeper的性能方面意味着它可以用于大型分布式体系。可靠性方面使其不会成为单点故障。严格的序次意味着可以在客户机上实现复杂的同步原语。
ZooKeeper is replicated. 和它所和谐的分布式进程一样,ZooKeeper本身也计划在一组称为合集的主机上举行复制。ZooKeeper服务的服务器必须相相互识。它们在长期存储中维护状态的内存映像以及事件日记和快照。只要大多数服务器可用,ZooKeeper服务就可用。
客户机毗连到单个ZooKeeper服务器。客户机维护一个TCP毗连,通过它发送哀求、获取相应、获取监视事故和发送心跳。假如到服务器的TCP毗连制止,客户机将毗连到另一台服务器。
ZooKeeper is ordered. ZooKeeper给每个更新贴上一个数字,这个数字反映了全部ZooKeeper事件的序次。后续操纵可以利用该序次实现更高级别的抽象,比犹如步原语。
ZooKeeper is fast. 在“以读取为主”的工作负载中,它尤其快。ZooKeeper应用步调运行在数千台呆板上,当读操纵比写操纵更常见时,它的性能最好,比率约为10:1。
2.1.1.2 数据模子和条理定名空间(Data model and the hierarchical namespace)
ZooKeeper提供的名称空间非常雷同于标准文件体系。名称是由斜杠(/)分隔的路径元素序列。ZooKeeper名称空间中的每个节点都由一个路径标识。ZooKeeper的条理名称空间:
2.1.1.3 节点和临时节点(Nodes and ephemeral nodes)
与标准文件体系差别,ZooKeeper名称空间中的每个节点都可以拥有与其关联的数据和子节点。这就像一个文件体系允许一个文件同时也是一个目次。(ZooKeeper的筹划目标是存储和谐数据:状态信息、设置、位置信息等,因此在每个节点上存储的数据通常很小,以字节到千字节为单元)。我们利用术语znode来表明我们在讨论ZooKeeper数据节点。
Znodes维护一个stat结构,此中包罗数据更改、ACL更改和时间戳的版本号,以允许缓存验证和和谐更新。每次znode的数据发生厘革,版本号就会增长。比方,每当客户机检索数据时,它也吸取数据的版本。
存储在名称空间中的每个znode中的数据是原子式读写的。读取获取与znode关联的全部数据字节,而写入则更换全部数据。每个节点都有一个访问控制列表(ACL),用于限定谁可以做什么。
ZooKeeper也有临时节点的概念。只要创建znode的会话处于运动状态,这些znode就会存在。当会话竣事时,删除znode。当您想要实现[tbd]时,临时节点非常有用。
2.1.1.4 更新条件和观察(Conditional updates and watches)
ZooKeeper支持手表的概念。Client可以在znode上设置手表。当znode发生更改时,将触发并删除一个手表。当一个手表被触发时,客户端收到一个数据包,说znode已经更改。假如客户机和ZooKeeper服务器之间的毗连断开,客户机将收到一个本地关照。这些可以用来[tbd]。
2.1.1.5 包管(Guarantees)
ZooKeeper黑白常快,非常简朴。但是,由于它的目标是作为构建更复杂服务(比犹如步)的根本,以是它提供了一组包管。这些都是:
Sequential Consistency - 来自客户机的更新将按发送序次应用
Atomicity - 更新乐成或失败。没有部分结果。
Single System Image - 无论服务毗连到哪个服务器,客户机都将看到雷同的服务视图。
Reliability - 一旦应用了更新,它将从当时起不绝一连到客户机覆盖更新为止。
Timeliness - 体系的客户端视图包管在肯定的时间范围内是最新的
2.1.1.6 Simple API
ZooKeeper的筹划目标之一是提供一个非常简朴的编程接口。因此,它只支持以下操纵:
create : 在树的某个位置创建节点
delete : 删除一个节点
exists : 测试某个位置是否存在节点
get data : 从节点读取数据
set data : 往一个节点里写入数据
get children : 检索节点的子列表
sync : 期待要传播的数据
2.1.1.7 实现(Implementation)
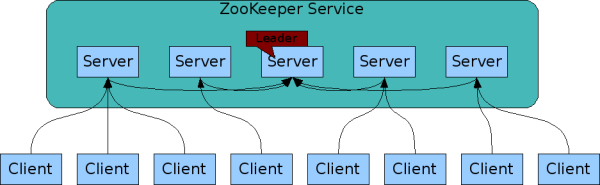
ZooKeeper Components 表现ZooKeeper服务的高级组件。除了哀求处理处罚器之外,构成ZooKeeper服务的每个服务器都复制本身的每个组件副本。
每个ZooKeeper服务器都为客户端提供服务。客户机仅毗连到一个服务器来提交哀求。读取哀求由每个服务器数据库的本地副本提供服务。更改服务状态的哀求(写哀求)由an agreement protocol处理处罚。
作为the agreement protocol的一部分,全部来自客户端的写哀求都被转发到一个名为leader的服务器上。其他的ZooKeeper服务器(称为跟随者)吸取来自向导者的消息发起,并就消息通报告竣划一。消息层负责在失败时更换向导者,并将跟随者与向导者同步。
ZooKeeper利用自界说原子消息通报协议。由于消息层是原子的,以是ZooKeeper可以包管本地副本不会发散。当leader吸取到写哀求时,它会盘算要应用写时体系的状态,并将其转换为捕获这个新状态的事件。
2.1.1.8 应用(Uses)
ZooKeeper的编程接口非常简朴。然而,利用它,您可以实现更高阶的操纵,比方同步原语、构成员关系、全部权等。一些分布式应用步调利用它来:[tbd: add uses from white paper and video presentation.]详情请参阅[tbd]
2.1.1.9 性能(Performance)
ZooKeeper被筹划成高性能.但真的是如许吗?Yahoo!的ZooKeeper开辟团队的研究结果。研究表明白实云云。(See ZooKeeper Throughput as the Read-Write Ratio Varies.)在读多于写的应用步调中,它的性能尤其高,由于写涉及同步全部服务器的状态。(读编号凌驾写通常是和谐服务的情况。)
Note:在3.2 r/w版本中,性能比前一个3.1版本进步了约2倍。
1.Failure and recovery of a follower
2.Failure and recovery of a different follower
3.Failure of the leader
4.Failure and recovery of two followers
5.Failure of another leader
2.1.1.10 可靠性(Reliability)
为了表现体系在注入故障时随时间的活动,我们运行了一个由7台呆板构成的ZooKeeper服务。我们运行了与从前雷同的饱和度基准测试,但这次我们将写百分比保持在30%稳定,这是预期工作负载的守旧比例。
2.1.1.11 ZooKeeper项目(The ZooKeeper Project)
ZooKeeper已乐成应用于许多工业范畴。Yahoo!作为雅虎的和谐和故障规复服务!Message Broker是一个高度可伸缩的发布-订阅体系,管理用于复制和数据交付的数千个主题。它被Yahoo!爬虫步调,它还管理故障规复。一些雅虎!广告体系也利用ZooKeeper来实现可靠的服务。
鼓励全部效户和开辟职员参加社区并贡献他们的专业知识。有关更多信息,请拜见Apache上的Zookeeper项目。
 |
猿人部落
( A20190523-0239 )
|
猿人部落
( A20190523-0239 )